Avatar Forcing:
Real-Time Interactive Head Avatar Generation for Natural Conversation
*Equal Contribution
[TL;DR] We present Avatar Forcing, a diffusion forcing-based head avatar generation model that can interact with users through their audio-visual signals at low latency on a single GPU (H100, 14GB). We improve interactive motions (e.g., active listening) through preference optimization by utilizing synthesized motion latents as losing samples.
Abstract
Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.
Methods
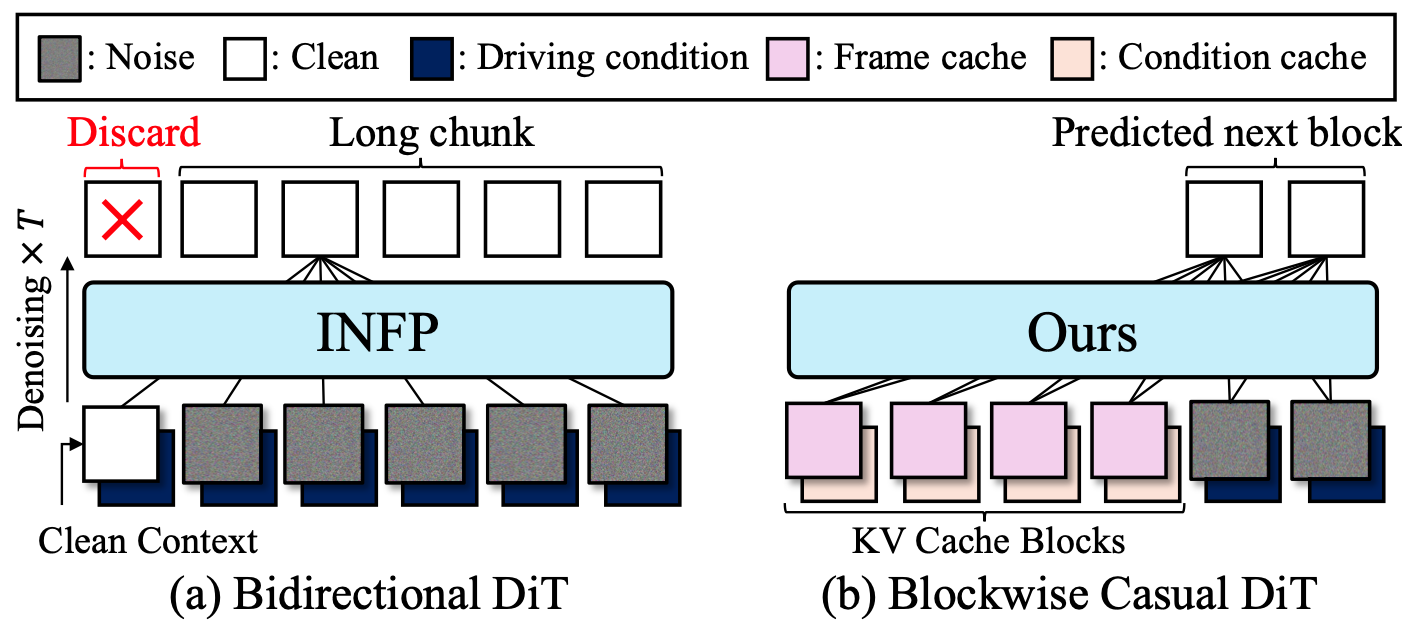
Causal Motion Generation with Diffusion Forcing
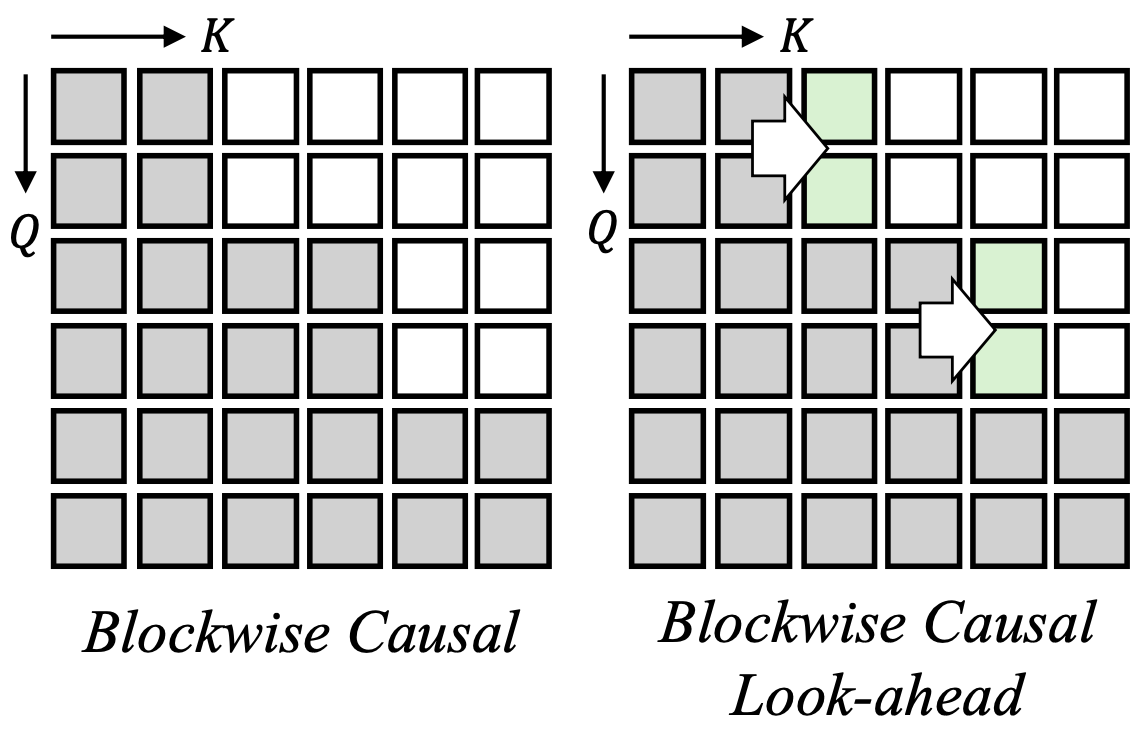
Conventional bidirectional DiT (used in INFP, CVPR 2025) generates long-range motion latent chunks that include future latents for temporal consistency. This design naturally restricts real-time interaction with users, apart from inference time. Avatar Forcing causally generates motion latents based on diffusion forcing, allowing interaction with users through their multimodal audio-visual signals. We introduce blockwise causal look-ahead masks for motion latent generation, which address temporal inconsistency between adjacent motion blocks.
Expressive & Engaging Interactive Motion Generation with Direct Preference Optimization (DPO)
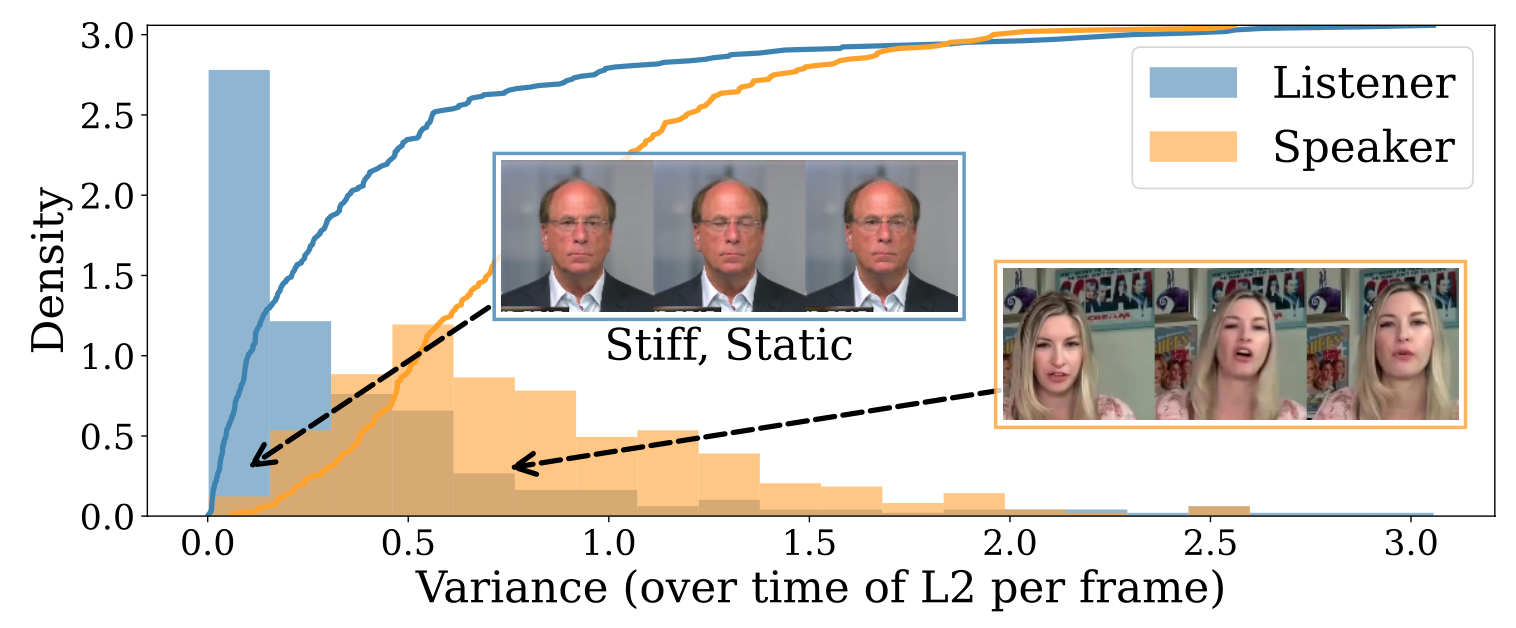
We observe that listening avatar videos show less expressive or less active motions than talking avatar videos. Modeling listening motion generation on these videos leads to stiff or static motion generation. This limitation highlights the necessity of quantifying activeness or naturalness, or alternatively using human labels; however, obtaining such consistent measurements or labels is difficult.
To tackle this problem, we introduce direct preference optimization (DPO) targeting more engaing and more active motion generation, leveraging synthesized non-active motion latents as less-preferred samples. This learning-from-losing paradigm significantly improves motion activeness and naturalness in a cost-effective way. We reformulate DPO post-training obejctive in the context of the diffusion forcing framework.
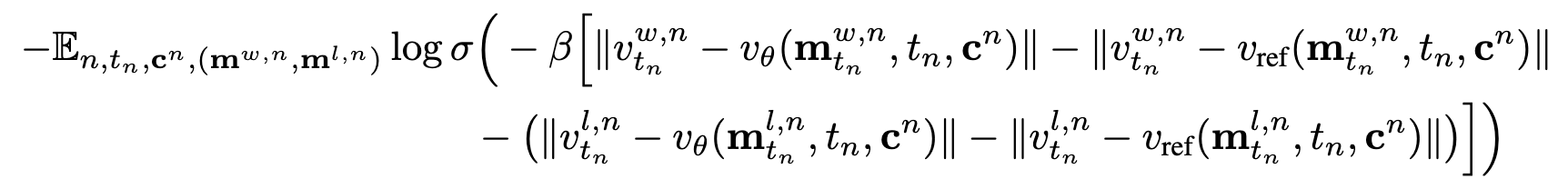
Results
Comparison with Baselines
Avatar Forcing outperforms baselines across four metric categories: Reactiveness, Motion Richness, Visual Quality, and Lip Sync. In particular, it achieves superior rPCC scores, which measure the correlation between user and avatar motions. Avatar Forcing also achieves strong performance in a human evaluation study.


We qualitatively compare Avatar Forcing with INFP using the demo video of INFP, as their official implementation is not available.
We also reprouce INFP, denoted as INFP*, and compare with it.
Ablation Studies
We conduct ablation studies on our key components: DPO and user's motion latent. Note the proposed DPO strategy significantly improves the reactiveness and motion richness. Additionally, we can generate more reactive facial expression (e.g., mirroring) when incorporating the user's motion for the avatar motion generation.


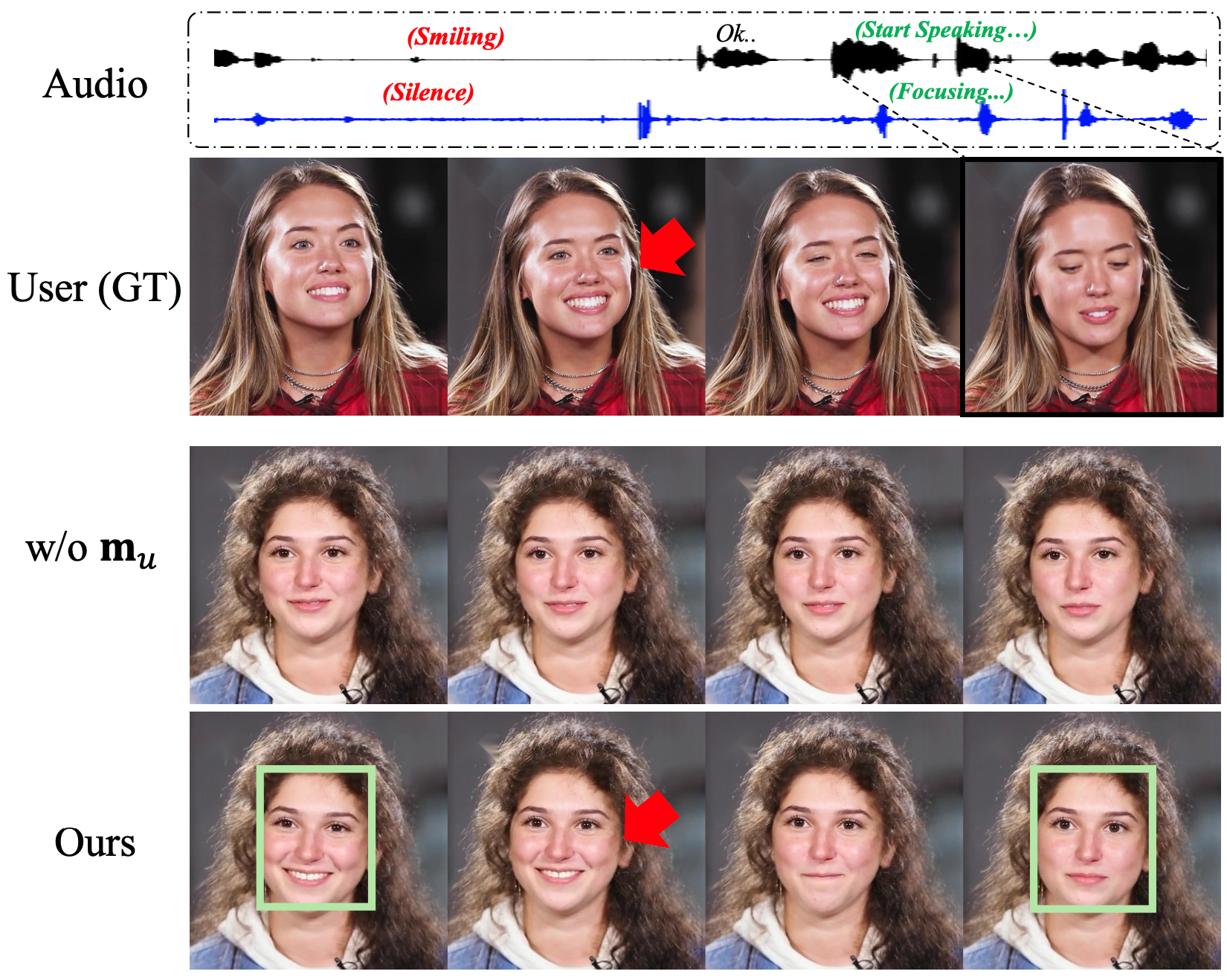
We provide the video results including the blockwise causal look-ahead mask that help better illustrate the ablation study.
Additional Results
Talking Avatar Generation
We compare our method with talking avatar geneartion methods on HDTF. Avatar Forcing can produce compretitive head avatar videos compared to SOTA methods.
Listening Avatar Generation
We compare our method with listening avatar geneartion methods on ViCo. Avatar Forcing can produce compretitive head avatar videos compared to SOTA methods.
Citation
@InProceedings{Ki_2026_CVPR,
author = {Ki, Taekyung and Jang, Sangwon and Jo, Jaehyeong and Yoon, Jaehong and Hwang, Sung Ju},
title = {Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {18074-18084}
}
Acknowledgement
The source images and audio are collected from datasets or generated by Gemini. This page is based on REPA.